Implementing a runtime version of JSX
Learning How to Think like a JSX Parser and Building an AST
JSX is one of the most commonly used syntax extensions out there. Originally JSX was parsed via a Facebook fork of Esprima — a JavaScript syntax parser developed by jQuery. As it gained momentum, Acorn took things to their hands and decided to make their own version of the parser which ended up being 1.5–2x faster than Esprima-fb, and is now being used by officially Babel.
It definitely went through an evolution, but regardless of its phase, all parsers had a similar output — which is an AST. Once we have an AST representation of the JSX code, interpretation is extremely easy.
Today we’re going to understand how a JSX parser thinks by implementing one of our own. Unlike Babel, rather than compiling, we’re going to evaluate the nodes in the AST according to their types, which means that we will be able to use JSX during runtime.
Below is an example of the final product:
class Hello extends React.Component {
render() {
return jsx`<div>Hello ${this.props.name}</div>`
}
}
ReactDOM.render(jsx`<${Hello} name="World" />`, document.getElementById('container'))Before we go ahead and rush to implementing the parser let’s understand what we’re aiming for. JSX
simply takes an HTML-like syntax and transforms it into nested React.createElement() calls. What
makes JSX unique is that we can use string interpolation within our HTML templates, so we can
provide it with data which doesn’t necessarily has to be serialized, things like functions, arrays,
or objects.
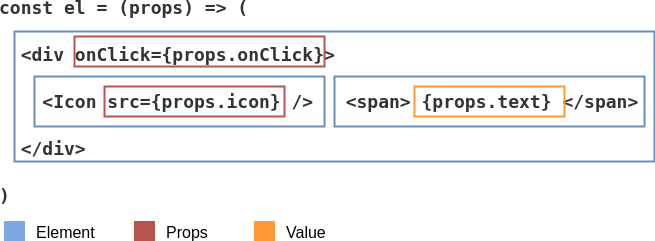
So given the following code:
const el = props => (
<div onClick={props.onClick}>
<Icon src={props.icon} />
<span>{props.text}</span>
</div>
)We should get the following output once compiling it with Babel:
const el = props =>
React.createElement(
'div',
{ onClick: props.onClick },
React.createElement(Icon, { src: props.icon }),
React.createElement('span', null, props.text)
)Just a quick reminder — the compiled result should be used internally by ReactDOM to differentiate
changes in the virtual DOM and then render them. This is something which is React specific and has
nothing to do with JSX, so at this point we have achieved our goal.
Essentially there are 3 things we should figure out when parsing a JSX code:
- The name / component of the React element.
- The props of the React element.
- The children of the React element, for each this process should repeat itself recursively.
As I mentioned earlier, it would be best if we could break down the code into nodes first and represent it as an AST. Looking at the input of the example above, we can roughly visualize how we would pluck the nodes from the code:
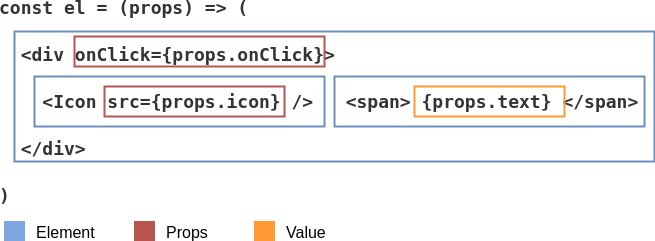
And to put things simple, here’s a schematic representation of the analysis above:
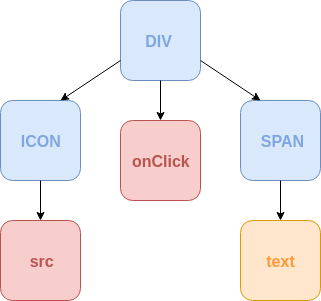
Accordingly, we’re going to have 3 types of nodes:
- Element node.
- Props node.
- Value node.
Let’s decide that each node has a base schema with the following properties:
- node.type — which will represent the type name of the node, e.g.
element,propsandvalue. Based on the node type we can also determine that additional properties that the node’s going to carry. In our parser, each node type should have the following additional properties:

- node.length —which represents the length of the sub-string in the code that the node occupies. This will help us trim the code string as we go with the parsing process so we can always focus on relevant parts of the string for the current node:

In the function that we’re going to build we’ll be taking advantage of ES6’s tagged templates. Tagged templates are string literals which can be processed by a custom handler according to our needs (see MDN docs).
So essentially the signature of our function should look like this:
const jsx = (splits, ...values) => {
// ...
}Since we’re gonna heavily rely on regular expression, it will be much easier to deal with a consistent string, so we can unleash the regexp full potential. For now let’s focus on the string part without the literal, and parse regular HTML string. Once we have that logic, we can implement string interpolation handling on top of it.
Starting with the Core — an HTML Parser
As I already mentioned, our AST will be consisted of 3 node types, which means that we will have to
create an ENUM that will contain the values element, props and value. This way the node types
won’t be hardcoded and patching the code can be very easy:
@@ -0,0 +1,5 @@
+┊ ┊1┊const types = {
+┊ ┊2┊ element: 'element',
+┊ ┊3┊ value: 'value',
+┊ ┊4┊ props: 'props',
+┊ ┊5┊}🚫↵Since we had 3 node types, it means that for each of them we should have a dedicated parsing function:
@@ -2,4 +2,40 @@
┊ 2┊ 2┊ element: 'element',
┊ 3┊ 3┊ value: 'value',
┊ 4┊ 4┊ props: 'props',
-┊ 5┊ ┊}🚫↵
+┊ ┊ 5┊}
+┊ ┊ 6┊
+┊ ┊ 7┊const parseElement = (str) => {
+┊ ┊ 8┊ let match
+┊ ┊ 9┊ let length
+┊ ┊10┊
+┊ ┊11┊ const node = {
+┊ ┊12┊ type: types.element,
+┊ ┊13┊ props: parseProps(''),
+┊ ┊14┊ children: [],
+┊ ┊15┊ length: 0,
+┊ ┊16┊ name: '',
+┊ ┊17┊ }
+┊ ┊18┊
+┊ ┊19┊ return node
+┊ ┊20┊}
+┊ ┊21┊
+┊ ┊22┊const parseProps = (str) => {
+┊ ┊23┊ let match
+┊ ┊24┊ let length
+┊ ┊25┊
+┊ ┊26┊ const node = {
+┊ ┊27┊ type: types.props,
+┊ ┊28┊ length: 0,
+┊ ┊29┊ props: {},
+┊ ┊30┊ }
+┊ ┊31┊
+┊ ┊32┊ return node
+┊ ┊33┊}
+┊ ┊34┊
+┊ ┊35┊const parseValue = (str) => {
+┊ ┊36┊ return {
+┊ ┊37┊ type: types.value,
+┊ ┊38┊ length: str.length,
+┊ ┊39┊ value: str.trim(),
+┊ ┊40┊ }
+┊ ┊41┊}Each function creates the basic node type and returns it. Note that at the beginning of the scope of each function I’ve defined a couple of variables:
let match- which will be used to store regular expression matches on the fly.let length- which will be used to store the length of the match, so we can trim the JSX code string right after and accumulate it innode.length.
For now the parseValue() function is pretty straight forward and just returns a node which wraps
the given string.
We will begin with the implementation of the element node, and we will branch out to other nodes as we go. First we will try to figure out the name of the element. If an element tag opener was not found, we will assume that the current part of the code is a value:
@@ -16,6 +16,19 @@
┊16┊16┊ name: '',
┊17┊17┊ }
┊18┊18┊
+┊ ┊19┊ match = str.match(/<(\w+)/)
+┊ ┊20┊
+┊ ┊21┊ if (!match) {
+┊ ┊22┊ str = str.split('<')[0]
+┊ ┊23┊
+┊ ┊24┊ return parseValue(str)
+┊ ┊25┊ }
+┊ ┊26┊
+┊ ┊27┊ node.name = match[1]
+┊ ┊28┊ length = match.index + match[0].length
+┊ ┊29┊ str = str.slice(length)
+┊ ┊30┊ node.length += length
+┊ ┊31┊
┊19┊32┊ return node
┊20┊33┊}Up next, we need to parse the props. To make things more efficient, we will need to first find the
tag closer, so we can provide the parseProps() method the relevant part of the string:
@@ -29,6 +29,15 @@
┊29┊29┊ str = str.slice(length)
┊30┊30┊ node.length += length
┊31┊31┊
+┊ ┊32┊ match = str.match(/>/)
+┊ ┊33┊
+┊ ┊34┊ if (!match) return node
+┊ ┊35┊
+┊ ┊36┊ node.props = parseProps(str.slice(0, match.index), values)
+┊ ┊37┊ length = node.props.length
+┊ ┊38┊ str = str.slice(length)
+┊ ┊39┊ node.length += length
+┊ ┊40┊
┊32┊41┊ return node
┊33┊42┊}Now that we’ve plucked the right substring, we can go ahead and implement the parseProps()
function logic:
@@ -51,6 +51,27 @@
┊51┊51┊ props: {},
┊52┊52┊ }
┊53┊53┊
+┊ ┊54┊ const matchNextProp = () => {
+┊ ┊55┊ match =
+┊ ┊56┊ str.match(/ *\w+="(?:.*[^\\]")?/) ||
+┊ ┊57┊ str.match(/ *\w+/)
+┊ ┊58┊ }
+┊ ┊59┊
+┊ ┊60┊ matchNextProp()
+┊ ┊61┊
+┊ ┊62┊ while (match) {
+┊ ┊63┊ const propStr = match[0]
+┊ ┊64┊ let [key, ...value] = propStr.split('=')
+┊ ┊65┊ node.length += propStr.length
+┊ ┊66┊ key = key.trim()
+┊ ┊67┊ value = value.join('=')
+┊ ┊68┊ value = value ? value.slice(1, -1) : true
+┊ ┊69┊ node.props[key] = value
+┊ ┊70┊ str = str.slice(0, match.index) + str.slice(match.index + propStr.length)
+┊ ┊71┊
+┊ ┊72┊ matchNextProp()
+┊ ┊73┊ }
+┊ ┊74┊
┊54┊75┊ return node
┊55┊76┊}The logic is pretty straight forward — we iterate through the string, and each time we try match the
next key->value pair. Once a pair wasn’t found, we return the node with the accumulated props. Note
that providing only an attribute with no value is also a valid syntax which will set its value to
true by default, thus the / *\w+/ regexp. Let’s proceed where we left of with the element
parsing implementation.
We need to figure out whether the current element is self-closing or not. If it is, we will return the node, and otherwise we will continue to parsing its children:
@@ -38,6 +38,22 @@
┊38┊38┊ str = str.slice(length)
┊39┊39┊ node.length += length
┊40┊40┊
+┊ ┊41┊ match = str.match(/^ *\/ *>/)
+┊ ┊42┊
+┊ ┊43┊ if (match) {
+┊ ┊44┊ node.length += match.index + match[0].length
+┊ ┊45┊
+┊ ┊46┊ return node
+┊ ┊47┊ }
+┊ ┊48┊
+┊ ┊49┊ match = str.match(/>/)
+┊ ┊50┊
+┊ ┊51┊ if (!match) return node
+┊ ┊52┊
+┊ ┊53┊ length = match.index + 1
+┊ ┊54┊ str = str.slice(length)
+┊ ┊55┊ node.length += length
+┊ ┊56┊
┊41┊57┊ return node
┊42┊58┊}Accordingly, we’re going to implement the children parsing logic:
@@ -54,6 +54,16 @@
┊54┊54┊ str = str.slice(length)
┊55┊55┊ node.length += length
┊56┊56┊
+┊ ┊57┊ let child = parseElement(str)
+┊ ┊58┊
+┊ ┊59┊ while (child.type === types.element || child.value) {
+┊ ┊60┊ length = child.length
+┊ ┊61┊ str = str.slice(length)
+┊ ┊62┊ node.length += length
+┊ ┊63┊ node.children.push(child)
+┊ ┊64┊ child = parseElement(str)
+┊ ┊65┊ }
+┊ ┊66┊
┊57┊67┊ return node
┊58┊68┊}Children parsing is recursive. We keep calling the parseElement() method for the current substring
until there’s no more match. Once we’ve gone through all the children, we can finish the process by
finding the closing tag:
@@ -64,6 +64,12 @@
┊64┊64┊ child = parseElement(str)
┊65┊65┊ }
┊66┊66┊
+┊ ┊67┊ match = str.match(new RegExp(`</${node.name}>`))
+┊ ┊68┊
+┊ ┊69┊ if (!match) return node
+┊ ┊70┊
+┊ ┊71┊ node.length += match.index + match[0].length
+┊ ┊72┊
┊67┊73┊ return node
┊68┊74┊}The HTML parsing part is finished! Now we can call the parseElement() for any given HTML string,
and we should get a JSON output which represents an AST, like the following:
{
"type": "element",
"props": {
"type": "props",
"length": 20,
"props": {
"onclick": "onclick()"
}
},
"children": [
{
"type": "element",
"props": {
"type": "props",
"length": 15,
"props": {
"src": "icon.svg"
}
},
"children": [],
"length": 18,
"name": "img"
},
{
"type": "element",
"props": {
"type": "props",
"length": 0,
"props": {}
},
"children": [
{
"type": "value",
"length": 4,
"value": "text"
}
],
"length": 12,
"name": "span"
}
],
"length": 74,
"name": "div"
}Leveling up — String Interpolation
Now we’re going to add string interpolation on top of the HTML string parsing logic. Since we still want to use the power of regexp at its full potential, we’re going to assume that the given string would be a template with placeholders, where each of them should be replaced with a value. That would be the easiest and most efficient way, rather than accepting an array of string splits.
[
'<__jsxPlaceholder>Hello __jsxPlaceholder</__jsxPlaceholder>',
[MyComponent, 'World', MyComponent]
]Accordingly, we will update the parsing functions’ signature and their calls, and we will define a placeholder constant:
@@ -1,16 +1,18 @@
+┊ ┊ 1┊const placeholder = `__jsxPlaceholder${Date.now()}`
+┊ ┊ 2┊
┊ 1┊ 3┊const types = {
┊ 2┊ 4┊ element: 'element',
┊ 3┊ 5┊ value: 'value',
┊ 4┊ 6┊ props: 'props',
┊ 5┊ 7┊}
┊ 6┊ 8┊
-┊ 7┊ ┊const parseElement = (str) => {
+┊ ┊ 9┊const parseElement = (str, values) => {
┊ 8┊10┊ let match
┊ 9┊11┊ let length
┊10┊12┊
┊11┊13┊ const node = {
┊12┊14┊ type: types.element,
-┊13┊ ┊ props: parseProps(''),
+┊ ┊15┊ props: parseProps('', []),
┊14┊16┊ children: [],
┊15┊17┊ length: 0,
┊16┊18┊ name: '',
@@ -21,7 +23,7 @@
┊21┊23┊ if (!match) {
┊22┊24┊ str = str.split('<')[0]
┊23┊25┊
-┊24┊ ┊ return parseValue(str)
+┊ ┊26┊ return parseValue(str, values)
┊25┊27┊ }
┊26┊28┊
┊27┊29┊ node.name = match[1]
@@ -54,14 +56,14 @@
┊54┊56┊ str = str.slice(length)
┊55┊57┊ node.length += length
┊56┊58┊
-┊57┊ ┊ let child = parseElement(str)
+┊ ┊59┊ let child = parseElement(str, values)
┊58┊60┊
┊59┊61┊ while (child.type === types.element || child.value) {
┊60┊62┊ length = child.length
┊61┊63┊ str = str.slice(length)
┊62┊64┊ node.length += length
┊63┊65┊ node.children.push(child)
-┊64┊ ┊ child = parseElement(str)
+┊ ┊66┊ child = parseElement(str, values)
┊65┊67┊ }
┊66┊68┊
┊67┊69┊ match = str.match(new RegExp(`</${node.name}>`))
@@ -73,7 +75,7 @@
┊73┊75┊ return node
┊74┊76┊}
┊75┊77┊
-┊76┊ ┊const parseProps = (str) => {
+┊ ┊78┊const parseProps = (str, values) => {
┊77┊79┊ let match
┊78┊80┊ let length
┊79┊81┊
@@ -107,7 +109,7 @@
┊107┊109┊ return node
┊108┊110┊}
┊109┊111┊
-┊110┊ ┊const parseValue = (str) => {
+┊ ┊112┊const parseValue = (str, values) => {
┊111┊113┊ return {
┊112┊114┊ type: types.value,
┊113┊115┊ length: str.length,Note how I used the Date.now() function to define a postfix for the placeholder. This we can be
sure that the same value won’t be given by the user as a string (possible, very unlikely). Now we
will go through each parsing function, and we’ll make sure that it knows how to deal with
placeholders correctly. We will start with the parseElement() function.
We will add an additional property to the node called: node.tag. The tag property is the component
that will be used to create the React element. It can either be a string or a React.Component. If
node.name is a placeholder, we will be taking the next value in the given values stack:
@@ -27,6 +27,7 @@
┊27┊27┊ }
┊28┊28┊
┊29┊29┊ node.name = match[1]
+┊ ┊30┊ node.tag = node.name === placeholder ? values.shift() : node.name
┊30┊31┊ length = match.index + match[0].length
┊31┊32┊ str = str.slice(length)
┊32┊33┊ node.length += length
@@ -72,6 +73,12 @@
┊72┊73┊
┊73┊74┊ node.length += match.index + match[0].length
┊74┊75┊
+┊ ┊76┊ if (node.name === placeholder) {
+┊ ┊77┊ const value = values.shift()
+┊ ┊78┊
+┊ ┊79┊ if (value !== node.tag) return node
+┊ ┊80┊ }
+┊ ┊81┊
┊75┊82┊ return node
┊76┊83┊}We also made sure that the closing tag matches the opening tag. I’ve decided to “swallow” errors rather than throwing them for the sake of simplicity, but generally speaking it would make a lot of sense to implement error throws within the parsing functions.
Up next would be the props node. This is fairly simple, we’re only going to add an additional regexp to the array of matchers, and that regexp will check for placeholders. If a placeholder was detected, we’re going to replace it with the next value in the values stack:
@@ -95,6 +95,7 @@
┊ 95┊ 95┊ const matchNextProp = () => {
┊ 96┊ 96┊ match =
┊ 97┊ 97┊ str.match(/ *\w+="(?:.*[^\\]")?/) ||
+┊ ┊ 98┊ str.match(new RegExp(` *\\w+=${placeholder}`)) ||
┊ 98┊ 99┊ str.match(/ *\w+/)
┊ 99┊100┊ }
┊100┊101┊
@@ -106,7 +107,9 @@
┊106┊107┊ node.length += propStr.length
┊107┊108┊ key = key.trim()
┊108┊109┊ value = value.join('=')
-┊109┊ ┊ value = value ? value.slice(1, -1) : true
+┊ ┊110┊ value =
+┊ ┊111┊ value === placeholder ? values.shift() :
+┊ ┊112┊ value ? value.slice(1, -1) : true
┊110┊113┊ node.props[key] = value
┊111┊114┊ str = str.slice(0, match.index) + str.slice(match.index + propStr.length)Last but not least, would be the value node. This is the most complex to handle out of the 3 nodes,
since it requires us to split the input string and create a dedicated value node out of each split.
So now, instead of returning a single node value, we will return an array of them. Accordingly, we
will also be changing the name of the function from parseValue() to parseValues():
@@ -23,7 +23,7 @@
┊23┊23┊ if (!match) {
┊24┊24┊ str = str.split('<')[0]
┊25┊25┊
-┊26┊ ┊ return parseValue(str, values)
+┊ ┊26┊ return parseValues(str, values)
┊27┊27┊ }
┊28┊28┊
┊29┊29┊ node.name = match[1]
@@ -57,14 +57,26 @@
┊57┊57┊ str = str.slice(length)
┊58┊58┊ node.length += length
┊59┊59┊
-┊60┊ ┊ let child = parseElement(str, values)
+┊ ┊60┊ let children = []
┊61┊61┊
-┊62┊ ┊ while (child.type === types.element || child.value) {
-┊63┊ ┊ length = child.length
-┊64┊ ┊ str = str.slice(length)
-┊65┊ ┊ node.length += length
-┊66┊ ┊ node.children.push(child)
-┊67┊ ┊ child = parseElement(str, values)
+┊ ┊62┊ const parseNextChildren = () => {
+┊ ┊63┊ children = [].concat(parseElement(str, values))
+┊ ┊64┊ }
+┊ ┊65┊
+┊ ┊66┊ parseNextChildren()
+┊ ┊67┊
+┊ ┊68┊ while (children.length) {
+┊ ┊69┊ children.forEach((child) => {
+┊ ┊70┊ length = child.length
+┊ ┊71┊ str = str.slice(length)
+┊ ┊72┊ node.length += length
+┊ ┊73┊
+┊ ┊74┊ if (child.type !== types.value || child.value) {
+┊ ┊75┊ node.children.push(child)
+┊ ┊76┊ }
+┊ ┊77┊ })
+┊ ┊78┊
+┊ ┊79┊ parseNextChildren()
┊68┊80┊ }
┊69┊81┊
┊70┊82┊ match = str.match(new RegExp(`</${node.name}>`))
@@ -119,10 +131,40 @@
┊119┊131┊ return node
┊120┊132┊}
┊121┊133┊
-┊122┊ ┊const parseValue = (str, values) => {
-┊123┊ ┊ return {
-┊124┊ ┊ type: types.value,
-┊125┊ ┊ length: str.length,
-┊126┊ ┊ value: str.trim(),
-┊127┊ ┊ }
+┊ ┊134┊const parseValues = (str, values) => {
+┊ ┊135┊ const nodes = []
+┊ ┊136┊
+┊ ┊137┊ str.split(placeholder).forEach((split, index, splits) => {
+┊ ┊138┊ let value
+┊ ┊139┊ let length
+┊ ┊140┊
+┊ ┊141┊ value = split
+┊ ┊142┊ length = split.length
+┊ ┊143┊ str = str.slice(length)
+┊ ┊144┊
+┊ ┊145┊ if (length) {
+┊ ┊146┊ nodes.push({
+┊ ┊147┊ type: types.value,
+┊ ┊148┊ length,
+┊ ┊149┊ value,
+┊ ┊150┊ })
+┊ ┊151┊ }
+┊ ┊152┊
+┊ ┊153┊ if (index === splits.length - 1) return
+┊ ┊154┊
+┊ ┊155┊ value = values.pop()
+┊ ┊156┊ length = placeholder.length
+┊ ┊157┊
+┊ ┊158┊ if (typeof value === 'string') {
+┊ ┊159┊ value = value.trim()
+┊ ┊160┊ }
+┊ ┊161┊
+┊ ┊162┊ nodes.push({
+┊ ┊163┊ type: types.value,
+┊ ┊164┊ length,
+┊ ┊165┊ value,
+┊ ┊166┊ })
+┊ ┊167┊ })
+┊ ┊168┊
+┊ ┊169┊ return nodes
┊128┊170┊}The reason why I’ve decided to return an array of nodes and not a singe node which contains an array
of values, just like the props node, is because it matches the signature of React.createElement()
perfectly. The values will be passed as children with a spread operator (...), and you should see
further this tutorial how this well it fits.
Note that we’ve also changed the way we accumulate children in the parseElement() function. Since
parseValues()returns an array now, and not a single node, we flatten it using an empty array
concatenation ([].concat()), and we only push the children whose contents are not empty.
The Grand Finale — Execution
At this point we should have a function which can transform a JSX code into an AST, including string interpolation. The only thing which is left to do now is build a function which will recursively create React elements out of the nodes in the tree.
The main function of the module should be called with a template tag. If you went through the
previous step, you should know that a consistent string has an advantage over an array of splits of
strings, since we can unleash the full potential of a regexp with ease. Accordingly, we will take
all the given splits and join them with the placeholder constant.
['<', '> Hello ', '</', '>'] // '<__jsxPlaceholder>Hello __jsxPlaceholder</__jsxPlaceholder>'Once we join the string we can create React elements recursively:
@@ -1,3 +1,5 @@
+┊ ┊1┊import React from 'react'
+┊ ┊2┊
┊1┊3┊const placeholder = `__jsxPlaceholder${Date.now()}`
┊2┊4┊
┊3┊5┊const types = {
@@ -6,6 +8,24 @@
┊ 6┊ 8┊ props: 'props',
┊ 7┊ 9┊}
┊ 8┊10┊
+┊ ┊11┊export const jsx = (splits, ...values) => {
+┊ ┊12┊ const root = parseElement(splits.join(placeholder), values)
+┊ ┊13┊
+┊ ┊14┊ return createReactElement(root)
+┊ ┊15┊}
+┊ ┊16┊
+┊ ┊17┊const createReactElement = (node) => {
+┊ ┊18┊ if (node.type === types.value) {
+┊ ┊19┊ return node.value
+┊ ┊20┊ }
+┊ ┊21┊
+┊ ┊22┊ return React.createElement(
+┊ ┊23┊ node.tag,
+┊ ┊24┊ node.props.props,
+┊ ┊25┊ ...node.children.map(createReactElement),
+┊ ┊26┊ )
+┊ ┊27┊}
+┊ ┊28┊
┊ 9┊29┊const parseElement = (str, values) => {
┊10┊30┊ let match
┊11┊31┊ let length
@@ -168,3 +188,5 @@
┊168┊188┊
┊169┊189┊ return nodes
┊170┊190┊}
+┊ ┊191┊
+┊ ┊192┊export default jsxNote that if a node of value type is being iterated, we will just return the raw string, otherwise
we will try to address its node.children property which doesn’t exist.
Our JSX runtime function is now ready to use!
If you wonder how did I structure this tutorial so nicely with steps and beautiful diffs — check out tortilla.academy by Uri Goldshtein.
Lastly, you can view the source code at the official GitHub repository, or you can download a Node.js package using NPM:
npm install jsx-runtimeJoin our newsletter
Want to hear from us when there's something new? Sign up and stay up to date!
By subscribing, you agree with Beehiiv’s Terms of Service and Privacy Policy.
Recent issues of our newsletterSimilar articles

Nextra 3 – Your Favourite MDX Framework, Now on 🧪 Steroids
MDX 3, new i18n, new _meta files with JSX support, more powerful TOC, remote MDX, better bundle size, MathJax, new code block styles, shikiji, ESM-only and more
Nextra 2 – Next.js Static Site Generator
Here are what the new version of Nextra 2 Framework includes.

Unleash the power of Fragments with GraphQL Codegen
The most important parts of Relay are the concepts of building and scaling applications, let's show how you can use these patterns in your existing projects.

GraphQL with TypeScript done right
How to get the most of React application types with GraphQL Code Generator.