GraphQL - Diving Deep

This blog is a part of a series on GraphQL where we will dive deep into GraphQL and its ecosystem one piece at a time
- Part 1: Diving Deep
- Part 2: The Usecase & Architecture
- Part 3: The Stack #1
- Part 4: The Stack #2
- Part 5: The Stack #3
- Part 6: The Workflow
The GraphQL specification was open sourced in 2015 by Facebook along with some basic implementations with a completely unique approach on how to structure, consume, transmit and process data and data graphs.
Today, the GraphQL spec and its implementations have been donated by Facebook to the GraphQL Foundation with open license for development and governance from the community, and it has been great so far. And today, the GraphQL foundation comprises not just of companies like Facebook but other organizational members as well.
It was a moment when a lot of people were convinced by its power, utility and promise that the rest became history.
And today, there is a GraphQL foundation which tries to ensure that GraphQL and the ecosystem thrives over time, a huge landscape of projects, a huge set of tools like this and this and these can just be few of the examples on how big the ecosystem has grown with a lot of languages, frameworks, tools supporting it as a first class citizen, so much so that even some huge enterprises are using it today as part of their stack.
GraphQL is at our heart at Timecampus, the heart of everything we do, and we wanted to share the love we have for GraphQL and the ecosystem and also the hard lessons we learnt along the way. And It’s not just GraphQL, we will be diving deep into a lot of Open Source Tools, Libraries, Frameworks, Software and Practices as we go along.
I am pretty sure that we have a lot to talk about as we go along. So, why not start the series with an FAQ? That’s what we are going to do here. I have put together a set of questions and answered them as well below.
If you are new to GraphQL, I would recommend you to start with these links before jumping into this blog post:
Introduction to GraphQL - Learn about GraphQL, how it works, and how to use it
And if you are keen to dig deep into the GraphQL Spec, it is hosted here
So, assuming you already know the basics of GraphQL, let’s jump right in.
Why should I move away from REST to GraphQL? What are the benefits?
I would start by saying that GraphQL does not make REST or any other channel of communication obsolete. It all boils down to your use case. For small projects, the simplicity of REST might overweight the advantages provided by GraphQL but as you have more teams, an evolving product, complex lifecycles and a data schema which gets bigger and bigger by the day, that’s when you will truly realize the value that GraphQL has to offer.
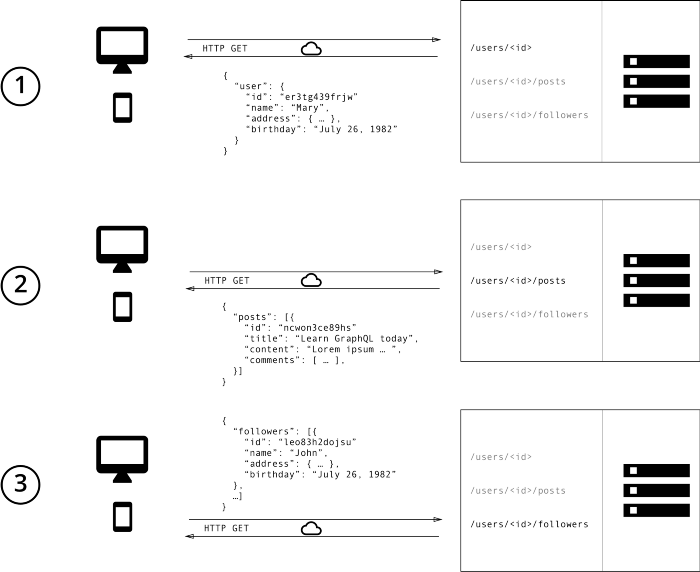
Credits: howtographql
In REST we try to structure different set of endpoints for different data paths, and if you see the REST Specification it does not offer a way to select only the data you want leading to over-fetching/under-fetching, does not offer type checking, no way to do introspection (unless you build an OpenAPI based documentation yourself) and this can also quickly become chatty since you have to end up calling different endpoints from the client to get different sets of data needed by the application. GraphQL solves all of these like this:
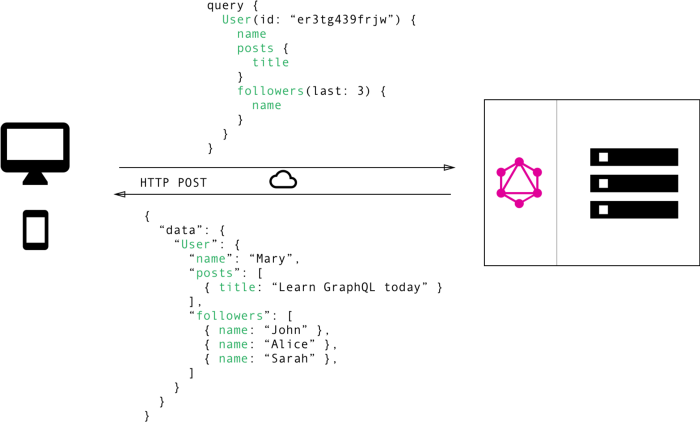
Credits: howtographql
And this is the beauty of it. It has a strong Type system, you can select just what you want avoiding over-fetching/under-fetching, you just have to talk to a single endpoint, the spec clearly defines about the execution of the queries (serial or parallel resolvers), its protocol independent unlike REST which relies on HTTP to do everything whereas you can even transmit your GQL queries through http, GRPC, Websockets — you name it.
What is the difference between HTTP, GRPC, GraphQL and others?
In summary, all of them are different. HTTP is a protocol by itself and does not define about the structure of the data transmitted via HTTP itself (The latest version is http 3), GRPC uses protocol buffers to send packets using http 2 as the protocol (and in the future can extend to use http 3 as well) and is often used for inter-service communications and GraphQL has nothing to do with the transport layer at all. It is just a specification for structuring and transmitting data to and fro different locations, and it does not even matter if you compress, encrypt or do anything with the queries and mutations as long as you have a logic to decompress or decrypt them on the server side. So, in summary they serve different purposes.
How do I version my GraphQL endpoints like I do in REST?
While there is nothing stopping you from having different versions to the GraphQL endpoints like
/v1/graphql /v2/graphql or something along the same lines, GraphQL recommends you to have a
continuously evolving version of your data graph. So, you can deprecate fields you no longer use,
removing them at a later point of time, add new fields as and when you need without affecting the
rest of the schema avoiding any conflicts which may occur otherwise.
What is the recommended way to define my schema?
Over time, people have developed a lot of abstractions on top of GraphQL that suddenly there seems like there are a lot of ways to define the schema.
Some ways including
- Writing the SDL directly as
.gqlor.graphqlfiles and then loading and parsing them - Using a library like Typegraphql to write your schema as code
- Define them directly as JS/TS objects as defined here
and there are more and more can evolve over time.
One thing to understand is that, if you are using Node.js graphql-js would typically be the underlying implementation of all libraries and ultimately everything would get converted to JS/TS objects typically an AST ultimately making all these as abstractions on top of the existing way to define schemas. Note that the implementation can differ a bit in other languages or even within Node.js if you are using other ways of implementation like graphql-jit
What are some GraphQL servers available and how do they differ?
If you are using Node.js there are a lot of implementations of GraphQL servers with a few being express-graphql, apollo-server, mercurius, graphql-helix and more. And if you are using other languages, you can see a great list here
Now, talking in context with Node.js it all varies depending on your use case.
- Are you dependent on Apollo or its ecosystem like federation? Go for apollo-server
- Do you use express as your framework? Use express-graphql
- Are you using fastify or are looking for a performant graphql library with comprehensive support? Go for mercurius
- Are you looking for making things as modular as possible, reduce bloat, and progressively extend functionality as you go along? Go for graphql-helix
Well, there are a lot of things that I have not mentioned but this is just a start to decide which suggests some factors to keep into account.
And infact, if you are keen on understanding how every graphql-server performs, I would recommend checking out this
What is the best way to leverage GraphQL with Typescript?
Considering both GraphQL and Typescript are strongly typed, we can actually combine them together to give us an amazing experience with the help of some tooling. This will help us to make the end-end request-response lifecycle strongly typed.
For instance, there are some amazing projects from The Guild like GraphQL Codegen which we can use for generating types based on our local/remote schema with great Typescript integration, and you have a lot of plugins/recepies you can use along with it as well.
Want to generate Typescript objects based on GQL documents? You can try out Typed Document Node
Or do you want to directly code the schema in Typescript and maintain strict types? Try Typegraphql
Well, there are more examples like these and this is just a start.
How do I setup my Dev environment to work on GraphQL?
While this needs a separate blog post all by itself, here are some examples.
- If you are using VSCode and are looking to enable syntax highlighting, validation, autocomplete, code-completion and so on, you can try using either VSCode GraphQL or Apollo GraphQL depending on which suits you better.
- If you are working with Typescript it would be better to have codegen setup as part of your workflow.
- If you want to validate your schema as and when you push to Version control to maintain sanity, setup something like GraphQL Inspector locally and in your CI/CD pipelines to maintain your sanity. If you use the Apollo ecosystem, it comes inbuilt in the Apollo Studio or the CLI tools which it gives you.
- Want to have ESLint support to enforce standards and maintain sanity across your team, try something like GraphQL ESLint and set it up with your preferred conventions.
- Setup a graphql-config and this will interface with other tooling like the codegen, VSCode GraphQL extension, GraphQL ESLint and more. This will help a lot since you have one config to manage all the interfacing tools. If you are using the Apollo Stack, you might need an apollo-config as well
- If you want to keep your GraphQL code as modular as possible with support for things like dependency injection, try something like GraphQL Modules
- Want to interface with multiple different data sources and integrations each with their own format but still have the experience of GraphQL when developing on top of them? Try something like GraphQL Mesh
- Want to use a tool to test GraphQL endpoints? You might need something like Insomnia, Postman, Hoppscotch or VSCode REST Client
And while I can talk more about this, it will never end cause the ecosystem is too huge and thriving.
I use REACT/Angular /Vue/Web Components. How do I integrate GraphQL with my components?
Again, the front end ecosystem is huge as well with its own set of tooling and libraries.
In my case, I typically try to work on the frontend without any framework (I use Lit Elements in my case, and we will have a separate blog on that soon), the tool you use completely depends on your requirements here.
- Apollo Client does have a good integration with these frameworks including React, iOS and Android — so, you might want to check that out
- Using React? Relay can be a great choice
- Using Vue? You can try Vue Apollo
- Using web components with Apollo Stack for GQL? You might want to check out Apollo Elements
- Using vanilla JS or TS or using web components and want to have a framework-independent way of
doing things? You can stick to the GraphQL codegen itself since it takes care of almost everything
underneath. Or if you want, you can also use Apollo Client’s vanilla version
@apollo/client/core. Apollo Elements does come with support for a lot of webcomponent libraries like Lit, Fast and Gluon or even without any of it and hence is quite flexible. - Or if you are just looking for a lightweight, performant and extensible GraphQL client, urql can be great as well.
- Or if you are looking for a minimal client which runs both in the Browser and Node, you can try GraphQL Request
Well, there are a lot of other ways we haven’t talked about and this is just a start.
What are some ways in which I can maintain performance while using GraphQL?
While GraphQL is really promising and helpful, you have to understand that like any technology or framework, it does come with its own set of problems, most of which have already been addressed. For instance, you might have heard about the N+1 problem, lack of caching, Query cost and complexity and so on and these have been addressed by some projects like the DataLoader, Persisted Queries, Caching and more which you can setup depending on your needs.
Ultimately it depends on the degree of the flexibility you want to offer. The more the flexibility, the more the cost. And it is your decision to decide it based on your use case.
What are some principles or standards to be followed when trying to build my datagraph architecture?
Some amazing people have already answered this here, and I highly recommend you to go through it before starting off your journey with GraphQL.
And if you are looking for some help with the rules and implementation details with respect to GraphQL, you can find a great doc on this here
While all of these are principles trying to guide you in the right direction, choose what is best for your use case and work with it.
How do I use GraphQL to interact with multiple sources of data?
One of the great examples of real-world implementation of this would be Gatsby where irrespective of the source of data, everything ultimately gets converted to GraphQL with plugins which can then be used in your workflow.
If you are to build it in the server side, either you can use an out-of-the-box solution like GraphQL Mesh or you can build it on your own since GraphQL just acts as an abstraction on top.
Or if you are on the apollo stack and want to connect to multiple data sources, you can have a look at apollo-datasource
Or you want to have a single ORM which closely resembles GraphQL like Prisma to integrate with multiple databases underneath
Ultimately it all boils down to how you structure your resolvers.
But, it does not stop here. Some databases also support GraphQL either via adapters or natively as well.
For e.g.
- Dgraph has a native GraphQL implementation
- Neo4j has a GraphQL adapter
- Hasura provides a GraphQL abstraction on top of your datasources
- Postgraphile can help if you use Postgres
Well, these are just some tools and services. There are more like this which can help.
The GraphQL spec is missing some types like DateTime, GeoLocation and more. How do I implement that?
Yes, this can be painful. But, it is by design to keep GraphQL as lean and lightweight as possible.
This is where GraphQL Scalars really help. You can define your own types and use them across your schema if they are not supported out of the box.
But, this can be tedious to implement and using a package like graphql-scalars can actually help since it comes inbuilt with some commonly used scalars which you can import and use.
There are some fields which I find myself repeating between various queries and mutations. How do I avoid doing this?
As the DRY principle goes, we can also make our operations modular with the help of GraphQL Fragments and then use those fragments as applicable anywhere.
Can’t I convert my Database schema directly to a GraphQL schema or generate a GraphQL schema?
While technically, it is possible and this is what database providers who offer a GraphQL layer on top use like Hasura or Graphcool — It is highly not recommended for client consumption, and I would also recommend you to read this to get more idea.
The main reason to this according to me is that GraphQL is meant to describe the Data Graph which revolves around the business/domain terminologies without involving the underlying technical complexity or details. For instance, one should not care about which table a specific field comes from, how to join, and so on.
It should just be about the business implementation for the end users so even a product manager who does not know about the underlying technical implementation can use it.
So, while you may use GraphQL as sort of an ORM for your databases or other data sources, exposing that directly to the clients is not a good option. Rather, there should be one more layer on top just to have it make sense for any end user and reduce the complexity for clients.
Are there some helpers libraries I can use to work with my GraphQL schemas?
Yes. GraphQL Tools (which was initially from Apollo and then taken over by the Guild) is one of those libraries which I highly recommend. You can do a lot of operations on your SDL or schema like merging multiple schemas, mocking your schemas with test data, building custom directives, loading remote schemas and so on which you can add as part of your stack.
What is the best strategy to distribute your schema? What if I am using Microservices with GraphQL?
While GraphQL is meant to be a single endpoint or provide a single unified view of the data for the clients, it is often not possible to do it all at one place since it can create a lot of bottlenecks. This is why Schema stitching or Apollo Federation came into place where multiple subschemas can contribute to the unified data graph.
While we can have a separate blog on Schema Stitching versus Federation sometime down the line, each have its own set of merits and demerits which you can understand only if you give both a try.
These videos can help get some basics (but a lot has changed since these videos were released especially with GraphQL Tools introducing Type Merging):
If you are still confused on what to go for, you can also read this blog about stitching and federation.
What are some GraphQL events/conferences to watch out for?
Since GraphQL was released, it garnered a huge interest in the community that a lot of conferences, events and meetups are held around the world keeping GraphQL as the main theme. Some of them are:
and there are more including meetups like these and these. You can find most of the previous sessions recorded on Youtube if you search for it.
How can I contribute to GraphQL and its ecosystem?
Every bit of help really counts since GraphQL foundation is run by a set of volunteers, and it’s all open source. You can:
- Write blogs like this to spread knowledge amongst the community
- Host meetups, speak in conferences about your experience and evangelize your best way possible.
- Contribute to the GraphQL spec with your suggestions (Some suggestions may take years to implement even if it is good, so you may need to have a lot of patience for this)
- Contribute to the ecosystem of tools leveraging GraphQL be it with documentation, tests, features, bug fixes, feedback and what not. It will definitely help.
- Facing a challenge with GraphQL which has not been solved before? Build your own tooling and contribute it to the community
- Create failing tests and reproducible projects
- Answer and help others on GitHub Issues, Discord, Stack Overflow, Twitter, Reddit. There are a lot of amazing GraphQL communities out there.
- Or if you want to take it to the next level and want to align your entire organization to help the GraphQL foundation, become its member and contribute.
There are a lot of small ways in which you can give back. Small or big does not matter. Every contribution counts.
Are there some case studies which can actually help me in the implementation?
Sure. While I can’t list them all here, here are some:
and you can find more here
Are there any publicly available GraphQL APIs which I can play around with?
Yes. While most of them would require you to authenticate, they are available for you to use. Some examples:
You can have a look at more like these here and play around with it.
I have a legacy architecture/stack as part of my organization. How do I incrementally migrate to GraphQL?
This is one of the places where GraphQL really shines. You need not move everything over at one piece. Here are some steps which might help.
- First, build a Datagraph for your entire business without worrying about the underlying logic/implementation. But don’t worry too much since you can always evolve this over time.
- Next, implement resolvers for every part of the schema in such a way that at phase 1, you just wrap your existing infrastructure with GraphQL. For instance, if your services use SOAP, you can add a GraphQL layer on top of it and calling that can all the SOAP service underneath and the client need not worry about it. You can use something like GraphQL Mesh or SOFA which can help in abstracting these. There is a good blog post on how to migrate from REST to GraphQL here.
- Change the client implementation one by one to call the GraphQL gateway instead of the legacy service.
- Now that you have GraphQL working in your ecosystem, you can incrementally move away from legacy implementations like SOAP without having to worry about how it will affect the clients progressively, one component at a time to use a native GraphQL implementation.
While this is one possible approach, this is not the only approach. There are a lot of other ways in which you can take this one step at a time without worrying about the legacy code you have.
How do I secure my GraphQL endpoint?
While the GraphQL spec itself does not recommend any specific way to do this and leaves it to the person implementing it, you can either use JWT, Cookies, Sessions and so on like you normally would when authenticating through other mechanisms.
How do I enable authorization to my GraphQL fields or schema?
This is very powerful in GraphQL since you can do a authorization at a very fine-grained level be it at the type level or at the field level. You can read this blog which suggests various ways in which you can do authorization.
You can also use libraries like GraphQL Shield which offers powerful middlewares to do this. But remember that authorization does come with attached cost since you are running a specific logic in/before your resolvers for all the fields which you want to authorize.
One often overlooked way is the use of directives to do authorization, one example of which is mentioned in this blog and this is very powerful and declarative. This way, you can specify the scope and add the directive to the respective fields in your SDL and it can do the job for you.
How do I enable real-time applications like Chat, auto-updates and so on in my application with GraphQL?
There are some options currently to do this.
- The first would be to use GraphQL Subscriptions which is part of the spec. You have to register the subscriptions upfront and also have support for Websockets if you want to do this.
- Another way is to do periodic long-time polling which can work at a small scale keeping your application stateless.
- An another way is to use live queries
Each option comes up with its own set of advantages and disadvantages again. Just remember that it is not often possible to keep your application stateless if you want something like Subscriptions. So, make sure you manage the state well and plan for failures and scaling your app.
And if you are new to subscriptions, you can probably watch this to get an idea about the basics of how subscription works.
What can I even do with introspection?
Introspection is typically used by the tooling to understand your GraphQL types and schema. For instance, tools like GraphQL Voyager can introspect your schema and build amazing graphs, and almost all extensions built around GraphQL leverage this power to understand your schema, types and everything around it.
Note that, it is recommended by experts to have introspection disabled in production due to security and performance reasons.
How do I do tracing of all operations in GraphQL?
There are various ways in which you can do this.
- If you want to do this on your own, you can send traces or contexts from within the resolvers using the Jaeger/OpenTelemetry SDKs and send all the information manually for tracing.
- OpenTelemetry has recently made support for GraphQL available. You can find it here
- But if you find yourself using the Apollo Stack, Apollo comes with its own tracing options like Apollo Tracing and you can read about it here
Just remember that Tracing will cause a lot of performance overhead, and it is highly recommended to have it off unless otherwise needed or probably use it only for specific layers of concern.
How do I handle errors gracefully?
Again, there are a lot of ways to do this.
- If you use the Apollo stack, you can use the apollo-errors package as documented here
- If you use express-graphql or want to use graphql-js natively, they expose error functions as well based on GraphQLError and can also use GraphQL extensions to augment with custom payload like error codes and so on which what you typically do when using servers like graphql-helix.
Now, this is the case since GraphQL does not have any dependence on the transport layer and thus status codes like 200, 400 or 500 may not make sense unless they are part of the response and the spec does not prescribe a specific way to do this as well.
Is GraphQL related to Graph databases in some way?
While GraphQL encourages you to think of your entire data as graphs of connected information since that would give a better insight into how to structure your schema leading to a unified data graph, it has no relation with Graph databases by itself since Graph databases act as a way to represent and store data in underlying storage systems to allow for fast traversal, walking and retrieval.
But, that being said, GraphQL and Graph Databases do have a lot of synergy between them. You can read about that here and here since its all about establishing the data schema and its relationships.
When exposing REST APIs to end users, I used to bill users based on API calls made. How do I do this for GraphQL?
This can be a challenging problem cause in GraphQL, it’s the clients which decide what to query/mutate and the server might not know that upfront unless you are using something like persisted queries.
And here, the CPU consumed can depend on the level of nesting of the queries, the operations which your resolvers do and so on making it difficult to estimate the costs upfront. You can find a detailed blog about this here.
- One way to handle this only allow persisted queries and approve them and assign costs to them upfront, but this can get tricky to manage over the long run as number of queries and mutations increase.
- Another way is to use custom cost directives as in this package manually specifying the complexity and cost and using that to bill your APIs
This is relatively a new area and still under exploration. For instance, Dgraph bills for Slash GraphQL based on the nodes accessed as mentioned here which can be valid for databases using GraphQL but not necessarily for GraphQL api by itself.
Here are some other resources which hosts FAQs on GraphQL as well
And there are more. Just google for it.
Hope this was informative. Do you have any question which I have not covered in this list or are you looking for some help? Let me know by reaching out to me @techahoy.
And if this helped, do share this across with your friends, do hang around and follow us for more like this every week. See you all soon.
Join our newsletter
Want to hear from us when there's something new? Sign up and stay up to date!
By subscribing, you agree with Beehiiv’s Terms of Service and Privacy Policy.
Recent issues of our newsletterSimilar articles
Announcing Accounts.js 1.0 Release Candidate
Introducing Accounts.js 1.0 Release Candidate, an end to end authentication and accounts management solution.

Building Open Source GraphQL Security
Learn how open-source boosts GraphQL security and explore defensive and offensive tools, resources, and best practices to protect your GraphQL APIs.

Open Source composition and validation library for Apollo Federation
Introducing MIT licensed drop-in replacement for the Apollo Federation composition library.

GraphQLConf 2023 Recap
Explore the highlights of GraphQLConf 2023. Learn about the latest trends in GraphQL, from gateway solutions to composite schemas and innovative projects.